J’ai conçu l’outil pour transformer des données en décisions concrètes, plutôt que de produire des statistiques sans usage.
Cadrage du besoin
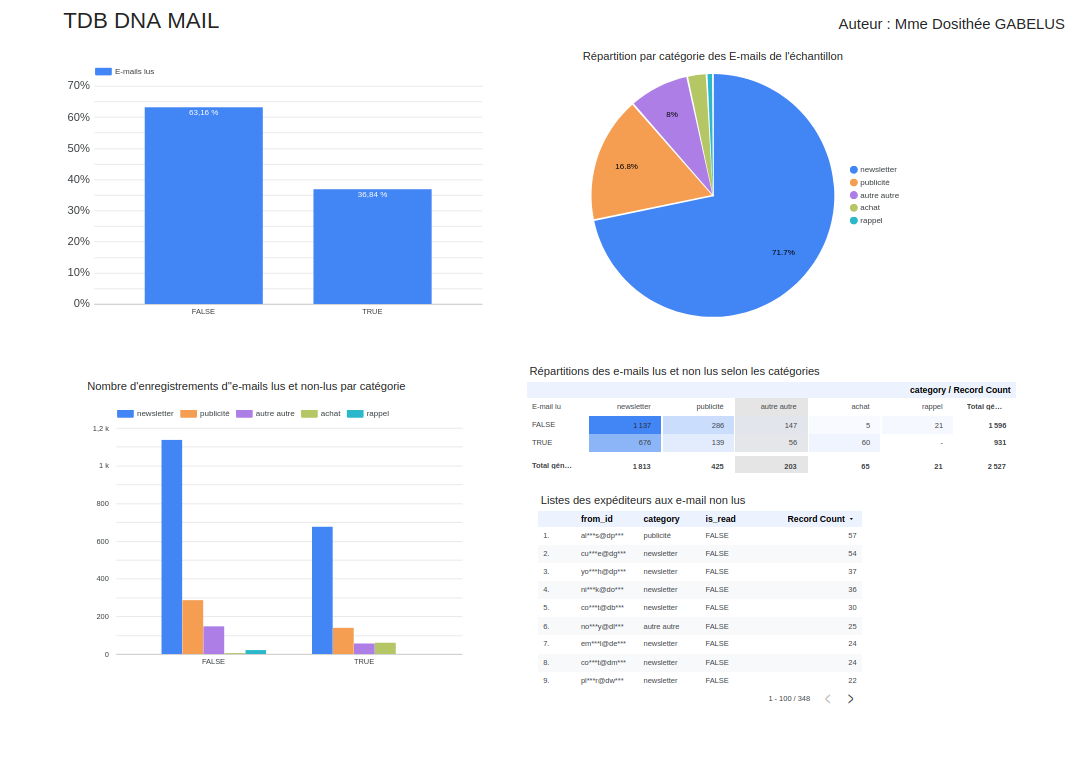
Réduire le bruit et le stock de non lus.
Identifier les catégories qui saturent la boîte mail.
Repérer les principales sources du non lu pour agir (désinscription, filtres, archivage).
Modèle de données minimal
Sélection de trois champs actionnables dès le départ : expéditeur (from_id), catégorie, statut lu ou non lu (is_read). Objectif : éviter de complexifier avant d’avoir un premier résultat exploitable.
Chaîne de traitement reproductible
Mise en place d’un flux rejouable : extraction, normalisation, enrichissement, stockage tabulaire. Objectif : relancer la même analyse après changements (filtres, désinscriptions) et comparer.
Visualisation et interprétation
Tableau de bord pour rendre visibles les priorités (lus vs non lus, répartition par catégorie, pression du flux). Règle : chaque indicateur doit déboucher sur une action (désinscrire, filtrer, archiver, prioriser).
Points de vigilance intégrés
Respect de la vie privée : données anonymisées et stockées localement. L’expéditeur est anonymisé par masquage partiel, ce qui peut regrouper plusieurs expéditeurs sous un même identifiant ; les analyses “top expéditeurs” restent des ordres de grandeur.
Sécurité : utilisation d’outils open source et auto-hébergés.